


최근 실무에서 구글 파이어베이스 푸시API가 버전업 되었는데,
가장 큰 원인은 HTTP/1.1 → HTTP/2.0 으로 전환으로 확인되었습니다.
이 과정에서 HTTP/2.0 의 동작방식에 관심이 생겨서
HTTP 의 버전별 차이점을 알아보게 되었습니다.
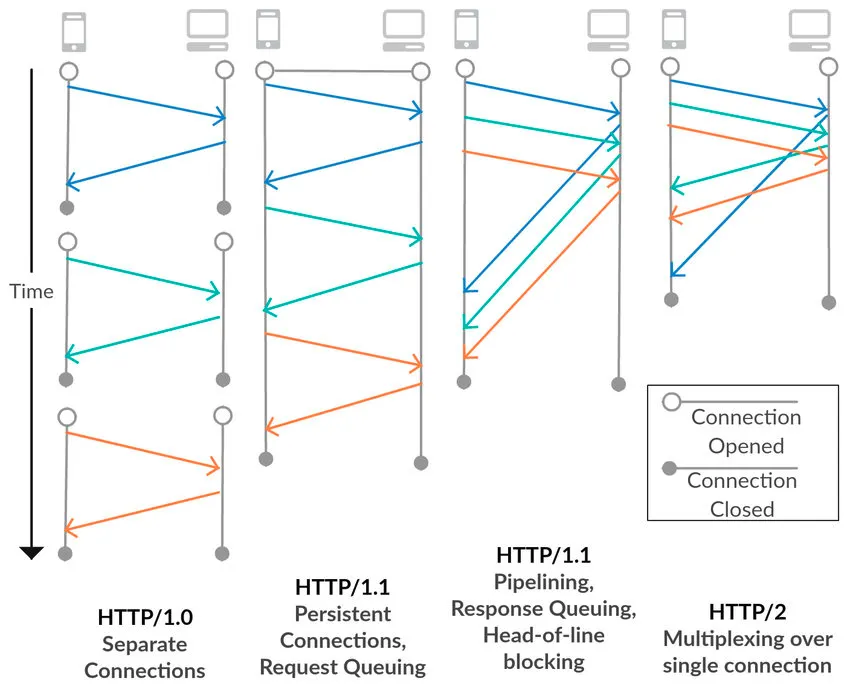
HTTP/1.0
•
한 연결당 하나의 요청을 처리하도록 설계
•
서버에게 요청 시 매번 연결과 해제의 과정을 반복해야 했기에 RTT가 오래걸린다는 문제
◦
RTT: 패킷이 목적지에 도달하고 나서 다시 출발지로 돌아오기까지 걸리는 시간 (패킷 왕복 시간)
HTTP/1.1
•
Persistent Connection 추가
◦
HTTP/1.0을 보완하여 매번 TCP 연결을 하는 것이 아니라 한 번 TCP 초기화를 한 이후에 keep-alive라는 옵션으로 일정 시간동안 연결 상태를 유지
•
Pipelining 추가
◦
TCP의 특성상 요청 후 응답을 기다려야하는 문제를 보완
◦
클라이언트는 앞 요청의 응답을 기다리지 않고 순차적으로 요청 전송, 서버는 요청이 들어온 순서대로 응답
•
HOL Blocking (Head Of Line Blocking) 문제
◦
앞의 요청(패킷)에 대한 응답이 늦어지면 뒤의 모든 요청들은 모두 blocking되어 응답이 지연됨
•
연속된 요청 간에 헤더의 많은 중복이 생긴다는 문제
HTTP/2.0
•
HTTP/1.x의 시간 지연 문제를 해결
•
Multiplexed streams (멀티플렉싱)
◦
HTTP/1.1의 Pipelining은 한번의 연결에서 여러 요청을 보낼 수는 있었지만 동시에 여러 요청을 처리하진 못했음
◦
하나의 커넥션 내에 여러개의 스트림(stream, 양방향 데이터 흐름)을 사용하여 송수신
◦
메시지가 이진화된 텍스트인 프레임(frame)으로 나뉘어 요청마다 구분되는 스트림(stream)을 통해 전달
◦
프레임(frame)이 각 요청의 스트림(stream)을 통해 전달되며, 하나의 커넥션 안에 여러개의 스트림(stream)을 가질 수 있게되어 다중화(multiplexing)가 가능해짐
◦
스트림(stream)을 통해 각 요청의 응답 순서가 의미가 없어져 HTTP/1.x의 HOL Blocking 문제 해결
.png&blockId=74ab2071-9ba6-4d69-a469-8679da2787cb)
•
Header Compression (헤더 압축)
◦
요청과 응답 헤더의 메타데이터를 압축해서 기존의 연속된 요청에서의 중복 헤더로 인한 오버헤드 문제를 해결
◦
이전에 표시된 헤더를 제외한 필드를 허프만 코딩을 활용해서 압축
•
Server Push (서버 푸시)
◦
클라이언트가 서버에 요청하지 않아도 클라이언트에게 필요한 리소스를 서버가 추가적으로 push해주는 기능
•
각 요청마다 stream으로 구분해 병렬적으로 처리함에도 불구하고 TCP 고유의 HOL Blocking이 여전히 존재하는 문제
◦
서로 다른 stream이 전송되고 있을 때, 하나의 Stream에서 유실이 발생되거나 문제가 생기면 결국 다른 Stream도 문제가 해결될 때 까지 지연되는 현상이 발생
HTTP/3.0
•
TCP 위에서 돌아가는 HTTP/2.0와는 달리 QUIC라는 계층 위에서 돌아가며 TCP기반이 아닌 UDP 기반
•
HTTP/2.0의 장점(멀티플렉싱 등)의 기능을 가지고 있음
•
초기 연결 설정 시 지연 시간 감소라는 대표적 특징 (UDP기반)
◦
초기 연결(통신 시작) 시 3-way handshaking 과정을 거치지 않아 1-RTT만 소요
◦
클라이언트와 서버거 한번 신호를 주고받은 후 바로 통신 시작
•
TCP의 stream은 하나의 chain으로 연결되는 것과 달리 각 stream당 독립된 stream chain을 구성하여 TCP의 HOL Blocking을 해결
마치며
자주 사용하는 웹사이트별로 HTTP2와 HTTP3 의 사용추이를 조사해보았는데,
구글, 네이버, 유튜브 등 대부분의 유명플랫폼들고 모두 사용하고 있고,
조금 개발을 신경쓰는 회사들도 많이 사용하고 있는걸로 확인되었습니다.
다만, 실무에 적용하기에는 브라우저 호환성문제나 적용방법, 문제대응 준비 등을
확인해봐야 되므로 확인해볼 필요는 있어 보입니다.
마침 쉽게 잘 정리된 글이 있어 소개하게 되었으니,
관심있는 분은 참고 해주시길 바랍니다.